AWS Glueのワークフローを触ってみた
はじめに
この記事は「いのべこ夏休みアドベントカレンダー 2021」の10日目の記事です。
記事の掲載内容は私自身の見解であり、所属する組織を代表するものではありません(お約束)。
Glueってなんだ
まずは、公式サイトを一部引用しよう。 全文は、公式サイトを見てほしい。
AWS Glue は、分析、機械学習、アプリケーション開発のためのデータの検出、準備、結合を簡単に行える、サーバーレスデータ統合サービスです。 AWS Glue はデータ統合に必要なすべての機能を備えているため、数か月ではなく、数分でデータを分析し、使用可能にします。
AWS Glue(分析用データ抽出、変換、ロード (ETL) )| AWS
…。LEViAは文字を理解するのが苦手なようだ。さっぱり分からん。
ということで、絵を描いた。

いきなり手書きで恐縮だが、絵に描いた項目を軽く説明すると以下の通り。
| 名前 | 説明 |
|---|---|
| Data Stores | データの取得先 AWSサービスのS3,RDS,Redshift,DynamoDB、もしくはJDBC接続が利用可能 JDBC接続を使うことで、EC2内に立てたPostgresに接続することもできるゾ |
| Workflows | CrawlersとJobsを結び付ける |
| Triggers | Workflows内で作成。CrawlersもしくはJobsを実行させる"引き金" |
| Crawlers | Data Storesからデータを取得し、MetadataTableに流し込む |
| Jobs | MetadataTableからデータを取得・加工し、DataTargetに流し込む |
| Data Target | データの吐き出し先。それ以上はDataStoresと同様の説明 |
| Connection | JDBC接続を行うために作成する「接続情報」 |
| オンデマンド/ スケジューリング/ Lambda |
実行方法の一例 |
実際にWorkflowsを作ってみるとしよう
作る処理としては、 CrawlersでS3に格納しているCSVを取得・MetaDataTableに吐き出しを行い、 JobsでMetaDataTableから取得・S3へCSVファイルを吐き出す。 データ加工はしないで右から左にデータを流すぞ。
■Crawlersの作成
作成した時の画面を1枚の画像にしてあるので、拡大してみてほしい。 URLなどは隠しているが、ご了承いただきたい。
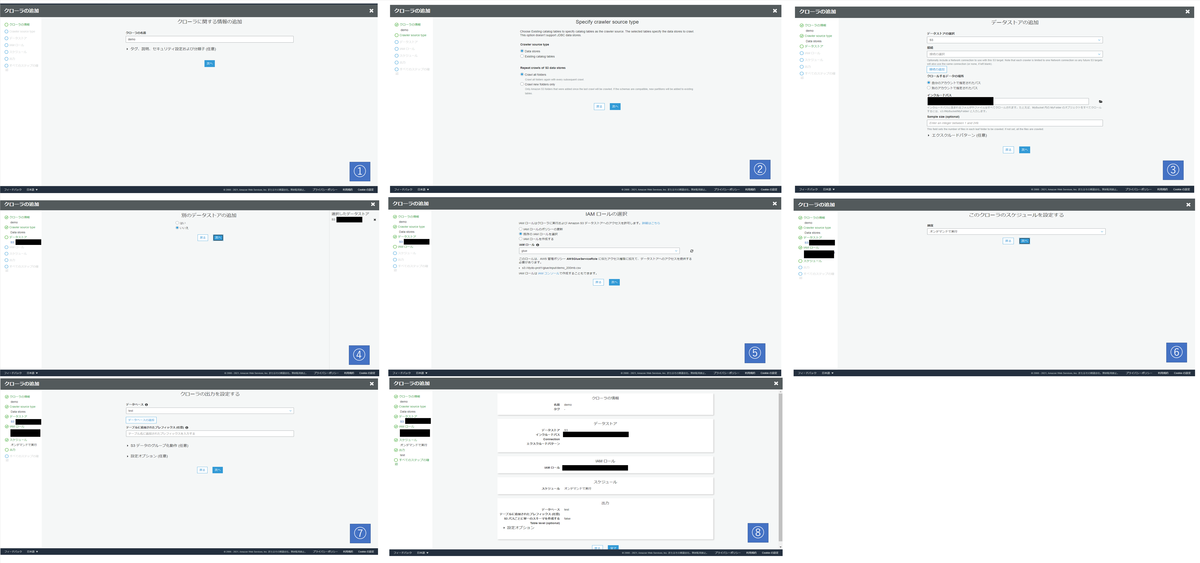
| 画像No | やること | 今回の設定値 |
|---|---|---|
| 1 | Crawlerを作成 | Crawler名にdemoを指定 |
| 2 | Crawlerの種類を指定 | デフォルト |
| 3 | DataStoreの追加 | 今回はS3に置いてあるCSVファイルをインプットとする。 ディレクトリだけ隠せばよいものを手を抜いて全部隠してしまった s3://~/demo_200mb.csvである。 |
| 4 | DataStoreの追加 | 2つ目のDataStoreは使わないので、いいえを指定 |
| 5 | IAMロールの選択 | 事前に作成したロールを指定 |
| 6 | スケジュール設定 | オンデマンドで実行 |
| 7 | Crawlerの出力先 | 事前に作成しているGlueDataCatalog内のデータベース、testを選択 |
| 8 | 確認画面 | 完了を押下すればよい |
[補足]IAMロール
事前に作成していたロールには、以下のポリシーを付与している。
- AWSGlueServiceRole
- S3バケットにアクセスするためのポリシー
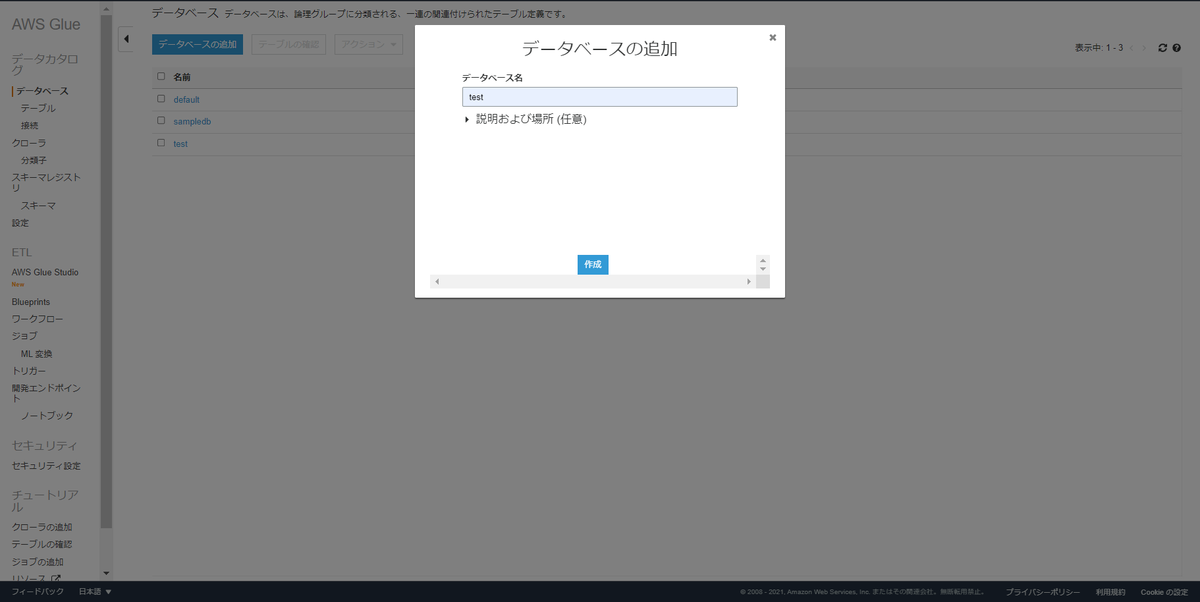
[補足]GlueDataCatalog内のデータベース
コンソール画面開いて、「データカタログ>データベース>データベースの追加」で作成している。
■Jobsの作成
Glue Studioで作成する。
1. Jobの新規作成
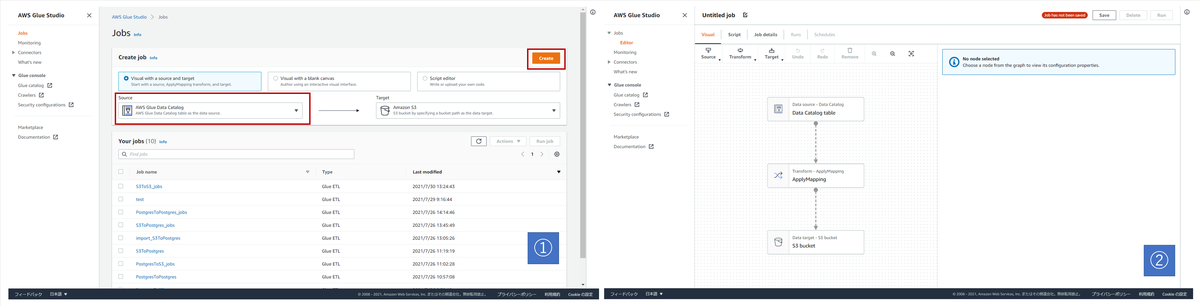
| 画像No | やること | 今回の設定値 |
|---|---|---|
| 1 | SourceとTargetを選択して Jobを新規作成する |
SourceはAWS Glue Data Catalog TargetはAmazon S3を選択 |
| 2 | 新規作成されたことを確認する | ここでの操作はない。次に進む |
2. Jobの詳細設定
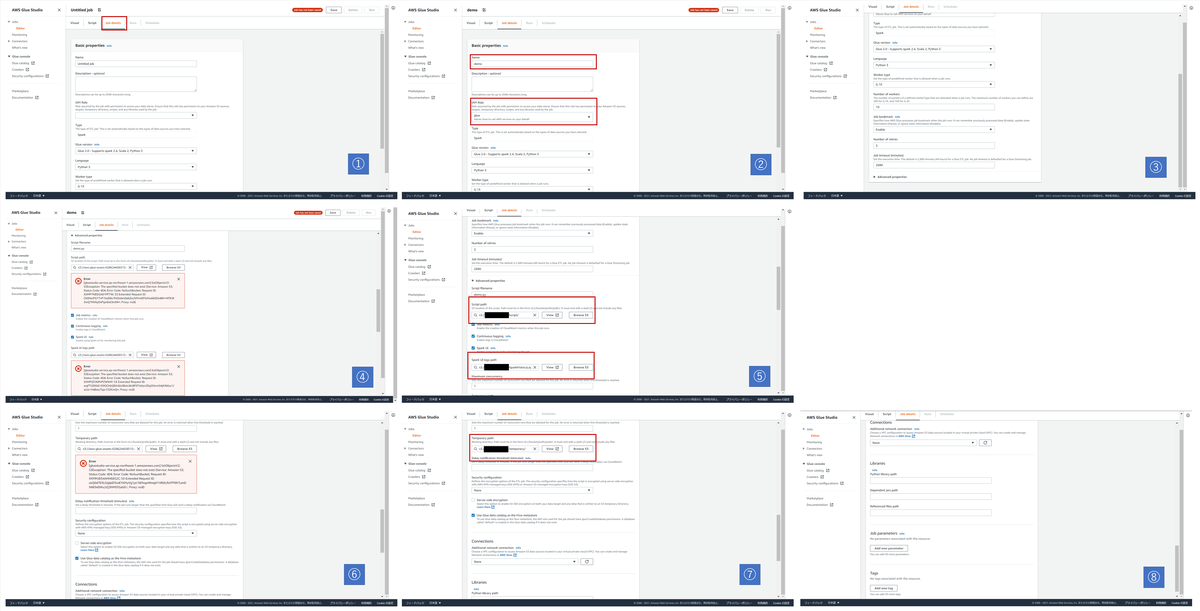
| 画像No | やること | 今回の操作 |
|---|---|---|
| 1 | Job detailsを表示する | 上部タブ「Job details」を選択 |
| 2 | Job名とIAMロールを選択 | Job名は「demo」 IAMロールはCrawler同様「glue」 |
| 3 | 実行タイプなどの確認 | 値はデフォルトのまま。 「▶Advanced properties」を選択 |
| 4 | [before]ScriptとLogの保存場所指定 | 設定前の画面 |
| 5 | [after]ScriptとLogの保存場所指定 | 事前に用意したS3バケット内のディレクトリを指定 |
| 6 | [before]Temporaryの保存場所指定 | 設定前の画面 |
| 7 | [after]Temporaryの保存場所指定 | 事前に用意したS3バケット内のディレクトリを指定 |
| 8 | 接続情報やライブラリの指定 | 今回は不要なので、デフォルトのまま |
3. Jobの処理を作る
データ加工したい場合は、ジョブの中で加工していくのだが今回はやらないゾー。

| 画像No | やること | 今回の操作 |
|---|---|---|
| 1 | [before]DataStoreを選択する | 設定前の画面 |
| 2 | [after]DataStoreを選択する | Databaseは「test」 Tableは「demo_200mb_csv」を選択 |
| 3 | DataMappingを設定する | 流し込む際のデータ型を指定するが、今回はデフォルト。 |
| 4 | [before]Targetを選択する | 設定前の画面 |
| 5 | [after]Targetを選択する | Formatは「CSV」に変更 CompressionTypeは「None」 のまま S3 Target Locationは事前に用意したS3バケット内のディレクトリを指定 |
■Workflowsの作成
・Workflowsの新規作成
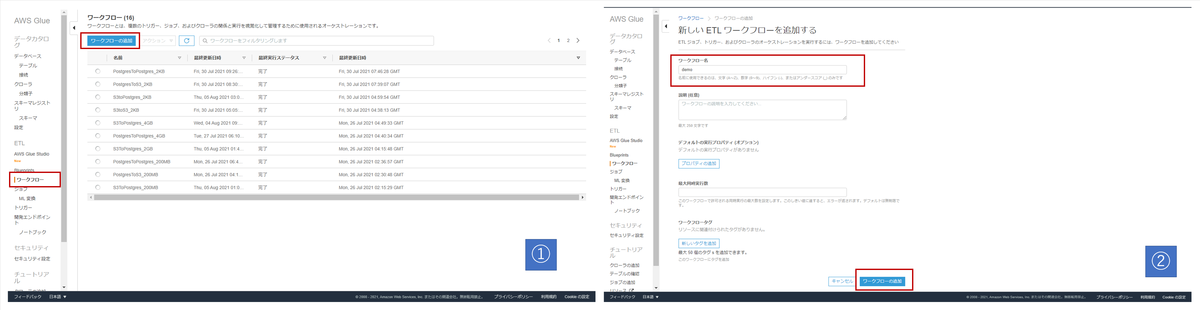
| 画像No | やること | 今回の操作 |
|---|---|---|
| 1 | Workflowsの画面を表示し、新規作成する | AWSコンソールの右側「ワークフロー」を押下する。 「ワークフローの追加」を押下する |
| 2 | Workflowsの名前を決める | 「demo」にした |
・CrawlersとJobsを紐づける
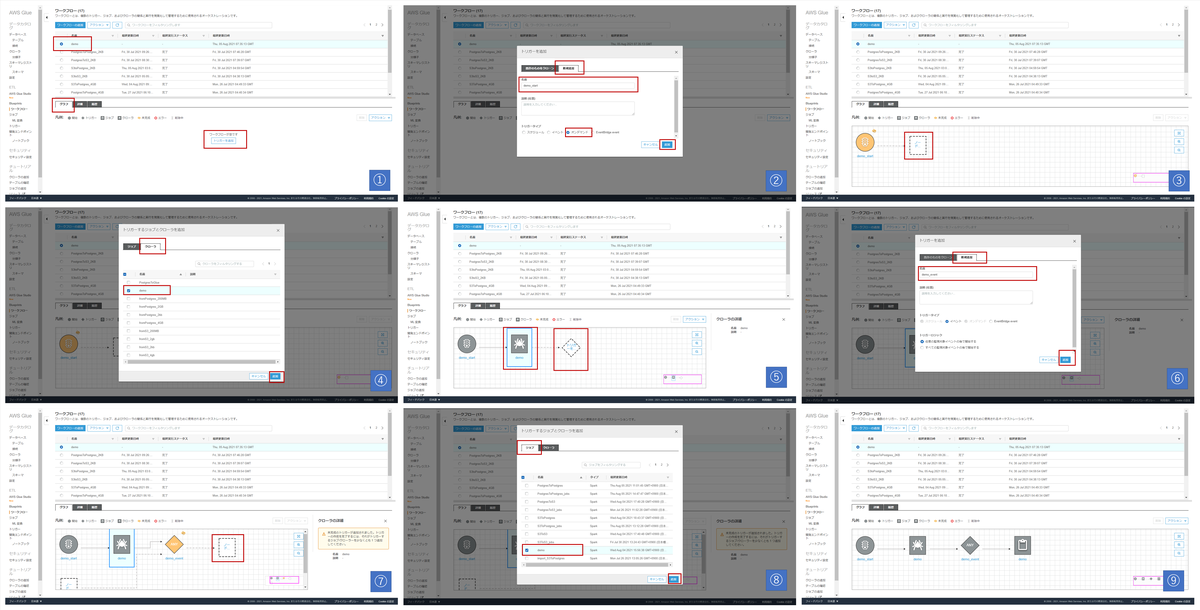
| 画像No | やること | 今回の操作 |
|---|---|---|
| 1 | Triggerを追加する | 「トリガーを追加」を押下 |
| 2 | Triggerを新規作成する | タブ「新規作成」を押下 Trigger名に「demo_start」 TriggerTypeはオンデマンド |
| 3 | 「demo_start」にCrawlersを紐づける | 「ノード」を押下する |
| 4 | 紐づけるCrawlersを選択する | タブ「クローラ」を押下 「demo」を選択 |
| 5 | Triggerを追加する | Crawlersの右側にある「トリガーを追加」を押下 |
| 6 | Triggerを新規作成する | タブ「新規作成」を押下 Trigger名に「demo_event」 TriggerTypeはデフォルトのまま「イベント」 |
| 7 | 「demo_event」にJobsを紐づける | 「ノード」を押下する |
| 8 | 紐づけるJobsを選択する | タブ「ジョブ」を押下 「demo」を選択 |
| 9 | 完成~~ |
・Workflowsの実行
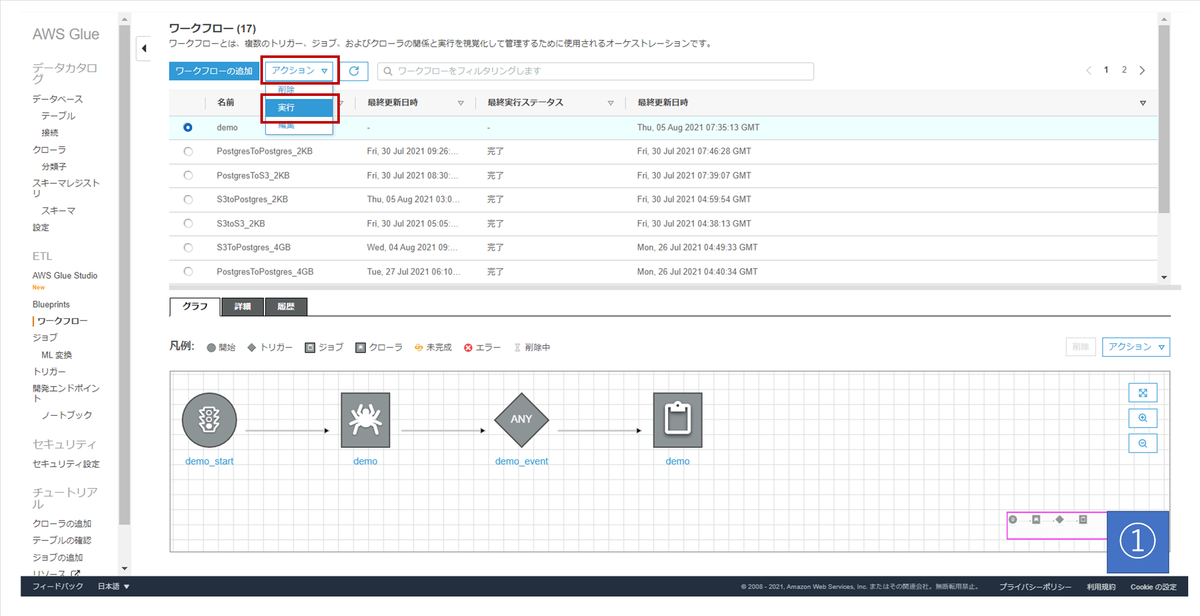
| 画像No | やること | 今回の操作 |
|---|---|---|
| 1 | Workflowsを実行 | 実行したいWorkflowsを選択 「アクション>実行」を選択 |
さいごに
Glueは一歩踏み出すのに勇気が必要だったが、踏み出してしまえばこちらのもんだった。
Glue Studioという便利な機能もあるので、AWSを触れる環境にある人はぜひ遊んでみてもらいたい。
今回Crawlersを使って処理を行ってみたが、
Crawlersを使わずJobsだけでデータの取得・加工・吐き出しが可能だ。
え??その方が処理時間が短くなるじゃあないかって?
まったくもってその通りである。
以上。